We have seen the Name Node is used to hold the information about the details of the data blocks stored in the Data Nodes. But what if the Name Node fails?
As a workaround there is something called 'Secondary Name Node'. The 'Name Node' and 'Secondary Name Node' works hand in hand so that if the 'Name Node' is down the 'Secondary Name Node' can fill the gap.
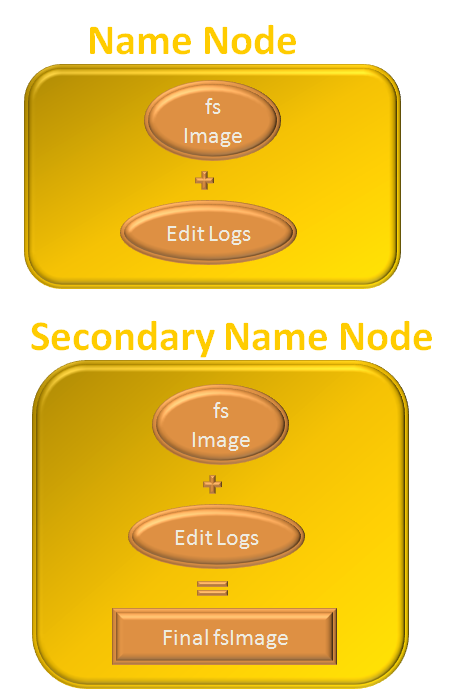
So, let's see the components fsimage and Edits in detail.
At first the 'fsimage' and the 'edit logs' is copied from Name Node to Secondary Name Node. Then in the Secondary Name Node, the 'fsimage' and the 'edit logs' are combined to get the 'final fsimage'. Which is then copied back to the 'Name Node' and replaced with the 'Name Node' of the 'Name Node'.