HDFS stands for Hadoop Distributed File System. As the name suggests it is a file system of Hadoop where the data is distributed across various machines. And each of the machines are connected to each other so that they can share data. Where an individual machine is called a NODE.

And the group of machines connected to each other is called a CLUSTER.
The individual machines are COMMODITY HARDWARES. i.e. They are low cost systems which we usually use at our home. But we have seen that at times the computer at our home breaks down. It can be due to hard disk crash or a CPU failure. The same thing can happen with the nodes(individual machines) in Hadoop. The nodes can be down and we might loose data.
The data loss problem is solved by replicating the data in more than one node. i.e. Hadoop stores the same data in three machines by default. So, if one machine fails the data can be retrieved from the other two.
Say we have a large file 'employee.csv' of 5GB and it has to be stored in HDFS. So, what Hadoop does is, it breaks the file of 5GB into parts, each consisting of 64MB. Once the file is broken, each block of 64MB is taken and is distributed among each of the the nodes in the cluster.
Say there are 5 Nodes A, B, C, D and E in the Cluster. Now, the first block of 64MB is taken and is placed in the first node A. Similarly, the second block is taken and is placed in the second node B. And the same process repeats for all the blocks until the blocks are completely distributed among all the 5 Nodes in the Cluster.
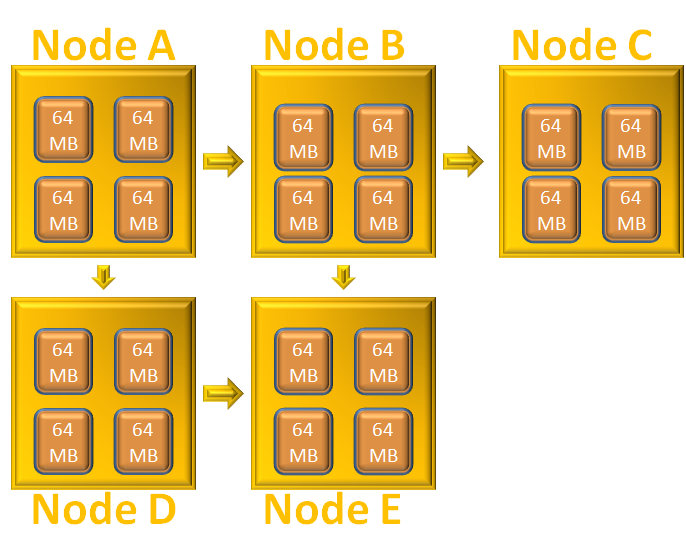
So, when the first block of 64MB is placed in the first node, the same time two copies of the same block is created and is placed in two other nodes in the cluster.

And in case the first node is down the data can be retrieved from any one of the two other nodes.
As we have seen the data is distributed across multiple nodes(i.e. machines) in a cluster. Now it's the responsibility of HDFS to keep a track on how the data should be distributed and managed. It solves this requirement by using a master slave architecture.
From the set of Nodes in the Cluster, it picks any one Node and names it as 'Name Node'. This 'Name Node' becomes the master and keeps track of all the distributed pieces stored in all the other Nodes. So, other than the Name Node all other Nodes becomes the slave and are called 'Data Nodes'.
The name 'Name Node' is quite justified as it contains the information of where the data is stored.
Same applies for the 'Data Node'. As it is the one where the actual data is stored.
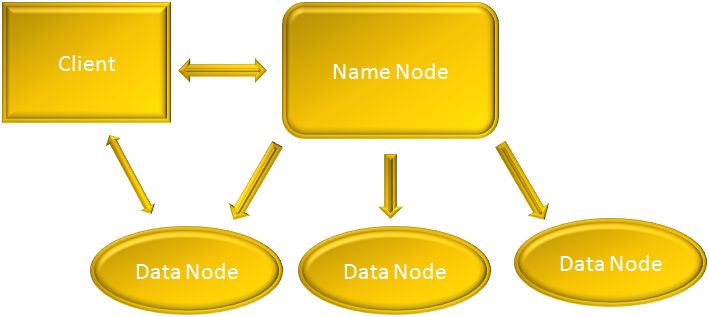
When the client sends a request, it is handled by the 'Name Node'. The 'Name Node' then figures out which 'Data Node' is available for storage. After identifying the 'Data Nodes' that are available it informs the client that which all Nodes are available. And the client sends the blocks of 64MB to those 'Data Nodes' for storage.
So, the Name Node is like a manager who knows which of the employees under him is working on what project. And if a client wants to get some work done, he has to approach the manager and the mannager decides how the work has to divided among the employees.
After the Name Node has informed the client about the free spaces on the Data Nodes. The client goes directly to those Data Nodes to store the data blocks. Let us see the below example to see how the data is replicated.